

로봇 인공지능 분야
9월 29일 목요일 오후 7:00, 인공지능대학원 4학기 첫 시험을 치른다. 로봇분야는 강화 학습의 역할이 크고 수학과 통계 개념이 중요하다. 어렵고 복잡한 내용이지만 공부한 내용을 간결하게 요약해보며 시험을 위한 준비를 해보려 한다. 복잡한 수식과 계산은 참고만 해두고 최대한 개념과 이론 설명 위주로 작성해본다.
Robots with AI
INTRO
인공지능? 추론, 의미 이해, 일반화, 과거로부터 학습, 어떻게 행동할 것인지 결정하는 능력을 갖춘 시스템. 로봇분야에서는 어떻게 행동할 것인지 결정하는 것, make decision to act이 중요하다.
The ability to reason, discover meaning, generalize, learn from past, make decision to act.
다양한 유형의 로봇
- Humanoid
- Mobile manipulator
- Drone
- Ground robot
- Manipulator
로봇을 위한 인공지능
로봇은 이미지, 소리, 촉각을 통해 상황을 인지 및 이해하고 어떻게 행동할지 결정한다.
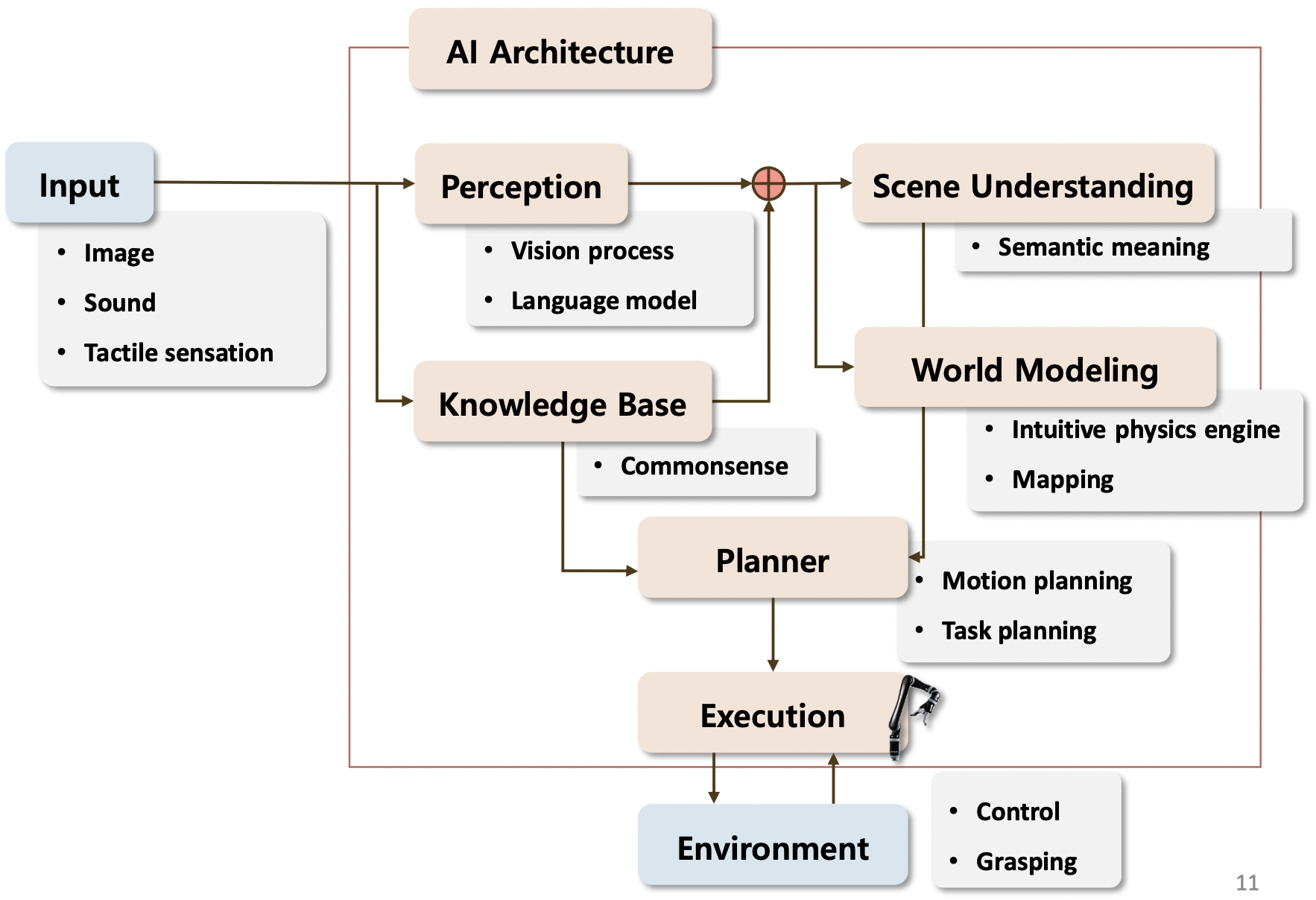
지각과 장면 이해_Perception & Scene Understanding
- Object detection
이미지 상에서 특정 클래스에 해당하는 물체를 찾아 바운딩 박스 형태로 표시해준다.
- Object recognition
탐지한 물체가 무엇이 자동차고 무엇이 사람인지 식별해준다.
- Image Segmentation
탐지 후 바운딩 박스가 아닌 Object에 테두리로 감싸 좀 더 정교하게 표현된다.
- 3D reconstruction
Object들을 관찰해서 주어진 일부로 원래의 모형을 3D로 구현한다.
- Image Captioning
이미지가 주어졌을 때 이미지를 설명하는 문장들이 출력된다.
- Relationships between object
이미지에 있는 물체들의 관계를 찾아 해석한다.
- Speech recognition
로봇이 사람의 언어를 듣고 판단하여 액션 하도록 연구
- Language grounding
언어가 주어졌을 때 그 언어가 물리적으로 어떤 의미를 가지고 있는지
- Speech to text(STT)
음성을 인식하여 텍스트 변환한다.
기본 지식_Knowledge Base
현실 세계에서 상식인 정보들이다. 예를 들어 사과는 과일이며 냉장고는 부엌에 위치한다는 정보들을 의미한다. 로봇 연구를 위해 기본적인 지식의 제공이 필요하다. 구글 등 여러 사이트에서 제공하기도 하지만 최근 트렌드는 상식적 요소를 중요하게 다루지 않으려 한다.
로봇이 길을 찾기 위한 기술_Navigation
- Mapping
주변 환경에 대한 지도
- Localization
자신(로봇)이 어디에 위치해있는지 아는 것
- Path Planning
어디로 이동할지 계획하고 결정하는 것
- Motion Planning
로봇의 팔을 어떻게 움직일지 계획하고 결정하는 것
- Task and Motion planning
어떤 작업, 임무를 해결하기 위한 움직임을 계획하는 것
- Grasping
물체를 어떻게 집을 것인지에 대한 연구
SLAM_Simultaneous localization and mapping
동시적 위치 추정 및 지도 작성이다. 즉 "로봇이 실시간으로 자신의 위치를 추정하고 주변 지도를 작성하는 기술", 일반 로봇청소기는 무작정 돌아다니며 언젠가 다 청소되겠지라는 방식이라면 SLAM이 적용된 로봇 청소기는 전체 공간을 인지하여 더욱더 효율적으로 청소한다.
- Occupancy grid map
어떤 환경에서 단순히 장애물이 있고 없는지만을 표현하는 지도이다.
- Topological Map
전체 공간에 중 일부에 대해서 그래프로 표현, 메모리가 효율적이다.
- 3D SLAM
Lidar 데이터 활용으로 3D 지도를 만든다.
- Semantic SLAM
지도에다가 좀 더 사람이 이해하는 것 같은 의미 정보들을 넣어준다. 로봇이 물을 떠 오려면 지도에서 부엌의 정보를 알고 있어야 하는데 이런 정보들을 가지고 있는 것
Motion Planning / Path Planning
현재 위치에서 목표한 지점까지 가기 위한 길을 찾는 정보
- Search based Path Planning
그래프 상에서 짧은 패스를 찾는 알고리즘을 사용해서 찾는다.
-Sampling based Planning
좀 더 효율적으로 환경이 주어졌을 때 랜덤 하게 노드를 뿌리고 연결하는 그래프를 만들고 경로를 찾는다( PRM, RRT )
Visual Navigation
로봇이 돌아다닐 때 센서 없이 오로지 비주얼 정보, 비전 정보를 통해서만 이동하는 것, 공장 자동화를 위해 많이 활용됨
- Grasp Detection
로봇이 물체를 집는 연구이다.
- Human-Robot Interaction through Language
사람과의 대화를 통해 가르치고 로봇이 이해하기 위한 연구이다.
처음에 로봇의 상태(Initial State)가 있고 이후 행동을 취한다. 그럼 상태 값이 바뀌게 되고 피드백(Reward)이 있을 것이다. 이 과정을 반복하면서 학습하는 것이 강화 학습의 기본적인 프로세스이다.
강화 학습에서 필요한 요소들 ( RL elements )
- Agent: 학습을 하는 주체_Learner
- Action: 무엇을 할지_What to do
- Environment: Agent 이외에 모든 것
- State: 현재 처한 상황을 표현하기 위한 모든 것
- Observe: Agent가 이해를 위해 주변을 관찰
- Terminal State
초기 상태에서 모든 과정을 완료한 상태이다. 목표했던 일을 성공했든 실패했든 마친 상태를 의미한다.
- Episode
초기 상태에서 시작해서 환경과 상호작용을 하다 보면 어느 순간 터미널 상태(Terminal State)가 되는데 이렇게 초기 상태에서 행동을 통해 터미널 상태까지 가는 과정을 에피소드라고 한다. 예를 들어 Grid world(2D로 된 환경을 일정한 크기의 그리드로 쪼개서 상태를 표현하는 방법)에서 시작 지점에서 목표지점까지 가는 과정이다. 꼭 성공하지 않고 실패하는 과정 또한 하나의 에피소드가 된다.
- Episode Task
Teminal State가 있는 Task를 의미한다.
- Continuing Task
Teminal State가 없는 Task를 의미한다. Agent가 작업을 끝내지 않고 계속 진행하고 있는 경우다.
- Policy
환경에 대한 관찰과 이해를 하고 어떤 행동을 취할 것인가에 대한 전략이다. State가 주어졌을 때 어떤 Action을 취할 것인가
short-term reward가 아닌 long-term reward로 봤을 때 좋은 전략을 찾는 것이 강화 학습의 목적이다.
Markov Decision Process_MDP
Markov property
의사결정을 위해서 주변 환경으로부터 정보를 받게 되는데 이런 정보들의 특성이다. 현재 state에서 다음 state로 변화하는 transition은 오로지 현재 state만 의존한다. 왜냐하면 현재 state에는 과거의 여러 과정을 거쳐서 행동한 것이므로 앞으로의 행동을 위한 정보를 충분히 포함하고 있다고 보는 것이다.
- Markov Chain
- Markov Reward Process
- Markov Decision Process
- Partially Observable MDP
- state-value function
현재 상태에서 이 policy를 따랐을 때 얼마나 좋고 가치 있는지 표현하는 값이다.
- action-value function
policy에 따라서 이 행동(action)을 했을 때 얼마나 좋고 가치 있는지 표현하는 값이다.
state가 변화함에 따라서 얻는 reward, 이 reward들의 합을 value function이라고 한다. state의 변화는 항상 policy에 의존한다. 강화 학습의 목표는 가장 좋은 policy를 찾는 것이다. 이것은 policy가 optimal value 또는 optimal action-value를 찾기를 기대하는 것이다. 이렇게 최적화된 value function을 찾는 것이 목표이며 이 과정을 MDP를 푼다고 표현하기도 한다.
[로봇인공지능]Robots with AI
What is Artificial intelligence? AI는 우리가 주어진 상황들을 이해하고 거기에 담긴 의미를 파악하고 그런 것들을 일반화할 수 있고 과거의 경험들로부터 배울 수도 있고 등등 생각할 수 있는 기술, 특
aiday.tistory.com
[로봇인공지능]강화학습 소개
강화 학습 강화 학습을 하는 주체를 agent라고 부른다. agent는 주변 환경과 상호작용(interaction)을 하면서 환경이 어떻게 변하는지 피드백을 받아 자신이 어떻게 행동해야 하는지 학습해서 발전된
aiday.tistory.com
[로봇인공지능]Markov Decision Process
Markov Decision Process(MDP) MDP는 RL, 강화 학습에서 중요한 핵심 이론이다. 이론을 알아보기 전에 Markov property에 대한 정의를 먼저 알아보면 agent가 환경에서 어떤 행동을 취하기 위해서는 의사결정이..
aiday.tistory.com
내용 참고
한양대학교 로봇인공지능 강의 자료
'AI' 카테고리의 다른 글
| Overfitting:오버피팅:과적합 방지, 해결을 위한 다양한 방법들 (52) | 2022.10.22 |
|---|---|
| 비전공자도 알수있는 Overfitting(과대적합)과 Underfitting(과소적합) 의미 (66) | 2022.10.11 |
| [로봇인공지능]Markov Decision Process (46) | 2022.09.28 |
| [로봇인공지능]강화학습 소개 (60) | 2022.09.27 |
| [로봇인공지능]Robots with AI (68) | 2022.09.26 |