

학습의 발전과 방향
지도 학습을 통해 인공지능 스피커, 자율주행 등 AI산업의 큰 폭의 발전을 계속해서 이루고 있습니다. 하지만 모든 데이터의 정답을 사람이 알려줘야 학습이 가능하기 때문에 많은 시간과 자원이 필요하다는 한계가 있어 사람의 지능과 가까운 강 인공지능이 탄생하기에는 지도 학습만으로 다소 어려움이 있습니다. 많은 연구자들은 미래의 인공지능은 비지도 학습이 완성시킬 것이라고 보고 있고 그 중심에는 GAN이 있다고 전망하고 있습니다.
기계의 학습 방법을 쉽게 알아보려면?
기계가 사람처럼 변해가는 과정 쉽게 알아보기(지도학습, 비지도학습, 강화학습)
기계가 사람처럼 행동하려면 뭐가 필요할까? 인공지능(artificial intelligence)이란 기계가 사람처럼 생각하고 결정하도록 만드는 과학분야입니다. 요즘 주변에서 AI가 붙은 제품을 많이 찾아볼 수
aiday.tistory.com

“만약 지능이 케이크라면 비지도 학습은 케이크의 본체다. 지도 학습은 케이크 본체의 겉에 발린 크림(icing)이고, 강화 학습은 케이크 위의 체리다. 우리는 크림과 체리를 어떻게 만드는지 안다. 그러나 케이크를 만드는 법은 모른다.”
생성적 적대 신경망, GAN
GAN, 한국에서는 간이라고 읽기도 하지만 보통 겐, 갠이라고 발음합니다. GAN은 이름만 봐도 의미를 파악할 수 있습니다. Generative:생성의, Adversarial:대립하는, 적대적인, Network :망이라는 뜻을 보면 무언가 두 부분 이상이 대립하고 있다는 걸 알 수 있습니다. 실제로 2가지 종류의 신경망을 가지고 있는 딥러닝 알고리즘입니다.
원리
생성적 적대 신경망의 말 그대로 생성자와 식별자가 서로 대립(Adversarial)하며 데이터를 생성(Generative)하는 모델(Network)을 뜻합니다. GAN을 최초로 고안한 이안 굿펠로(Ian Goodfellow)가 자주 사용하는 위조 화폐의 예시로 개념적인 내용을 알아보겠습니다.
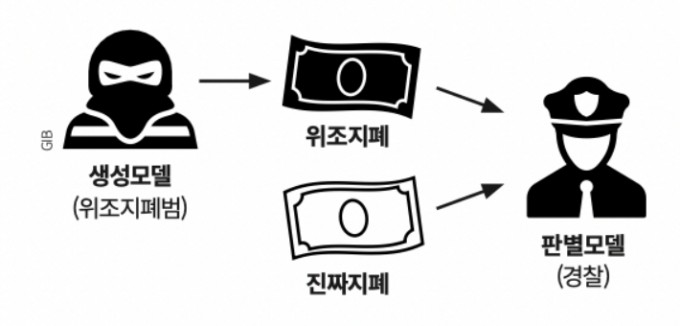
위조지폐범 생성 모델(G:Generator)은 경찰을 속이기 위해 열심히 위조지폐를 발행합니다. 경찰 판별 모델(D:Discriminator)은 진짜 지폐와 위조지폐를 감별(Classify)하려고 노력합니다. 이 경쟁 과정에서 둘 다 성능이 발전되고 결과적으로 판별 모델은 가장 헷갈리는 50% 확률에 수렴하게 되어 진짜와 가짜를 구별할 수 없는 상태가 됩니다.
GAN은 결국 판별 모델이 진짜 데이터와 가짜 데이터를 구분하지 못하도록 하는 것이 목표입니다.
학습과 구조
생성과 판별을 위한 두 개의 뉴럴 네트워크를 만듭니다. 첫 번째로 진짜 데이터로 판별 모델이 진짜를 분류할 수 있도록 학습시킵니다. 두 번째는 생성 모델이 가짜 데이터를 생성하고 판별 모델은 진짜와 가짜를 분류하도록 학습합니다. 생성 모델은 분류 모델을 속이는 방향으로 발전시키고 분류 모델은 판별을 반복하면서 서로가 서로를 발전시키는 구조를 이루고 있습니다. 이 과정이 반복되면서 생성 모델과 분류 모델이 서로를 적대적인 경쟁자로 인식하여 두 모델 모두 발전하게 됩니다.

목적함수
판별 모델은 입력받은 데이터가 진짜 데이터라고 판단하면 1을 리턴, 가짜 데이터라고 판단하면 0을 리턴하는 모델입니다. 이때 판별 모델의 목적함수는 아래와 같이 정의됩니다. 진짜 데이터이면 1, 가짜 데이터라면 0이 되도록 하는 목적함수입니다. 생성 모델의 경우도 목적함수가 같지만 아래의 식에서 max가 아닌 min을 목표합니다.

활용사례
딥 페이크(Deep Fake)
최근 독립운동가의 과거 사진을 활용하여 살아 움직이는 듯한 영상을 만들기도 하고 악의적으로 가짜 포르노 영상을 만들기도 하는 기술 모두 GAN기반으로 만들어졌습니다.
엔터테인먼트 산업
딥 페이크와 비슷하게 이미 사망한 배우나 가족을 현실 세계로 소환하거나 과거 모습을 재현합니다.
마케팅 산업
적대적 기계학습을 활용하여 요즘 많은 기업이 가상 인간을 모델로 활용합니다. 이것의 장점은 비용도 절감되고 완벽한 외모와 스타일링, 나이를 안 먹기 때문에 활동 기간이 길고 사생활 이슈가 없습니다.
예술 산업
사진을 디즈니 애니메이션 풍으로 변경하기도 하고 특정 화가의 화풍을 학습하여 적용할 수 있습니다.
데이터 증대
또 다른 인공지능의 학습을 위해서 가짜 데이터를 대량으로 생산할 수 있습니다.


내용 참고
한양대학교 인공지능융합대학원 딥러닝 개론 강의자료, 동아사이언스
'AI' 카테고리의 다른 글
| [로봇인공지능]Monte-Carlo Methods (45) | 2023.04.12 |
|---|---|
| 포털 사이트를 위협하는 ChatGPT, 소개 | 사이트 | 가입 | 특징 | 사용법 | 오류 | 블로그 자동화 (by.OpenAI) (7) | 2023.01.30 |
| 배치 정규화:Batch Nomalization 이론/특징/알고리즘/한계/장단점 (66) | 2022.10.24 |
| Overfitting:오버피팅:과적합 방지, 해결을 위한 다양한 방법들 (52) | 2022.10.22 |
| 비전공자도 알수있는 Overfitting(과대적합)과 Underfitting(과소적합) 의미 (66) | 2022.10.11 |